Smart Data Type
The Future of Sorting and Searching: Introducing Smart Data Type
Introduction
In today’s data-driven world, the efficiency of sorting and searching algorithms plays a crucial role in computational performance. Traditional data types are static structures that merely store values, requiring external algorithms to perform operations on them. But what if data types could learn and optimize themselves? Introducing the Smart Data Type (or
Intelligent Data Type
), a revolutionary approach to data processing that can enhance efficiency in AI, databases, and large-scale data management.
The Problem: Limitations of Traditional Sorting and Searching
Conventional sorting and searching algorithms, such as Bubble Sort, Merge Sort, and Binary Search, follow predefined steps to process data. While these methods are effective, they become computationally expensive when handling massive datasets. These algorithms lack adaptability and require constant reprocessing when new data is introduced.
One common scenario is sorting a list of people based on height. If a coach asks a group of individuals to arrange themselves by height, they naturally exchange positions without requiring complex traversals or calculations. This intuitive approach inspired the concept of an intelligent data structure that responds dynamically to commands, reducing computational complexity.
What is Smart Data Type?
A Smart Data Type is an intelligent, self-optimizing data structure that:
Learns from previous operations to improve efficiency.
Optimizes sorting and searching based on past interactions.
Interacts with algorithms in a way that reduces redundant computations.
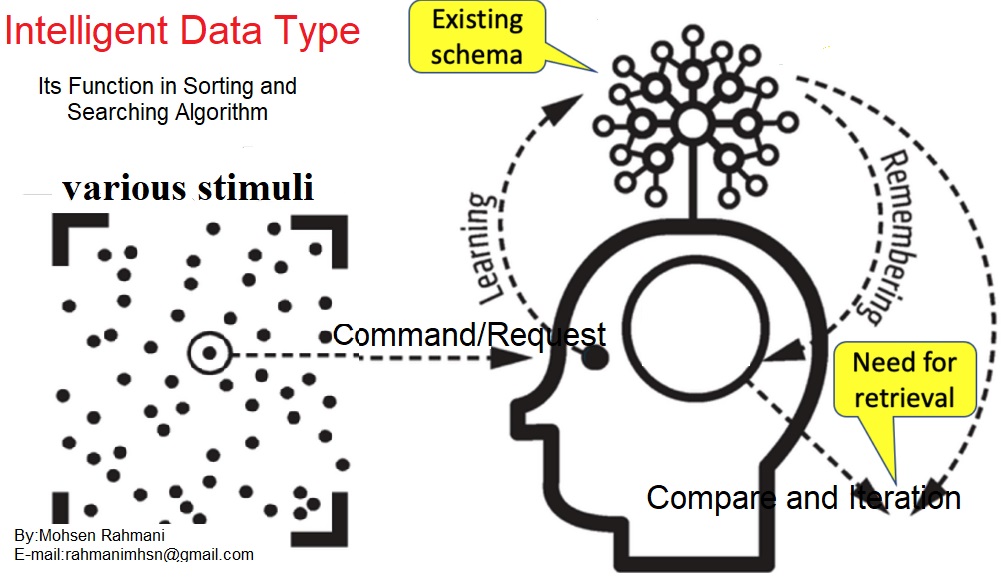
Rather than passively storing values, a Smart Data Type actively participates in processing, much like a trained system that can interpret and execute commands with minimal overhead.
How Smart Data Type Works
Unlike traditional approaches, where external algorithms manipulate data, a Smart Data Type processes and organizes itself based on learned patterns. Imagine a dataset where elements recognize sorting requests and autonomously adjust themselves. This is similar to human cognitive behavior, where learned experiences allow faster decision-making.
For example, consider a classroom attendance system where students respond when their names are called. Rather than the system scanning the entire dataset, each element (student) inherently knows when to respond, significantly reducing search time.
Key Features of Smart Data Type
Adaptive Learning: Learns from previous searches and sorts to improve future operations.
Dynamic Optimization: Adjusts its structure in real-time, minimizing redundant computations.
Efficient Processing: Reduces time complexity by intelligently handling queries.
Scalability: Suitable for large-scale datasets, AI-driven applications, and real-time processing.
Potential Applications
Smart Data Type can be a game-changer in:
Artificial Intelligence & Machine Learning – Faster data retrieval in AI models.
Databases & Big Data – Improved indexing and search efficiency.
Cybersecurity – Intelligent filtering of threats in real-time.
Financial Systems – Faster transaction processing and risk analysis.
Conclusion
The concept of Smart Data Type represents a paradigm shift in data processing. By integrating intelligence into data structures, we can move beyond rigid, predefined algorithms toward a more dynamic and efficient approach. This innovation has the potential to transform various industries, reducing computational costs and enhancing performance.
🚀 Join the discussion! What are your thoughts on Smart Data Types? Could they redefine the future of computing?
🔗 Read more on LinkedIn
🔗 Follow the conversation on Twitter
#AI #MachineLearning #DataScience #Innovation #SortingAlgorithm #SmartDataType
 ما همه روزه از محصولات و امکانات فن آوری اطلاعات استفاده میکنیم . امروزه یکی از بزرگترین و مهمترین تولیدات کشورهای پیشرو در مبحث تکنولوژی اطلاعات است ولی با این وجود دانش عمومی جامعه و حتی قشر تحصیل کرده در خصوص مفاهیم و پایه های این موضوع بسیار سطحی و ناقص است .
ما همه روزه از محصولات و امکانات فن آوری اطلاعات استفاده میکنیم . امروزه یکی از بزرگترین و مهمترین تولیدات کشورهای پیشرو در مبحث تکنولوژی اطلاعات است ولی با این وجود دانش عمومی جامعه و حتی قشر تحصیل کرده در خصوص مفاهیم و پایه های این موضوع بسیار سطحی و ناقص است .